The Recursive least squares (RLS) adaptive filter is an algorithm which recursively finds the filter coefficients that minimize a weighted linear least squares cost function relating to the input signals. This is in contrast to other algorithms such as the least mean squares (LMS) that aim to reduce the mean square error. In the derivation of the RLS, the input signals are considered deterministic, while for the LMS and similar algorithm they are considered stochastic. Compared to most of its competitors, the RLS exhibits extremely fast convergence. However, this benefit comes at the cost of high computational complexity.
Motivation
RLS was discovered by Gauss but lay unused or ignored until 1950 when Plackett rediscovered the original work of Gauss from 1821. In general, the RLS can be used to solve any problem that can be solved by adaptive filters. For example, suppose that a signal d(n) is transmitted over an echoey, noisy channel that causes it to be received as

where  represents additive noise. We will attempt to recover the desired signal
represents additive noise. We will attempt to recover the desired signal  by use of a
by use of a  -tap FIR filter,
-tap FIR filter,  :
:

where ![{\displaystyle \mathbf {x} _{n}=[x(n)\quad x(n-1)\quad \ldots \quad x(n-p)]^{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/09eb921b307dabe5f3f396085912215d09c02114) is the vector containing the
is the vector containing the  most recent samples of
most recent samples of  . Our goal is to estimate the parameters of the filter , and at each time n we refer to the new least squares estimate by
. Our goal is to estimate the parameters of the filter , and at each time n we refer to the new least squares estimate by  . As time evolves, we would like to avoid completely redoing the least squares algorithm to find the new estimate for
. As time evolves, we would like to avoid completely redoing the least squares algorithm to find the new estimate for  , in terms of
, in terms of  .
.
The benefit of the RLS algorithm is that there is no need to invert matrices, thereby saving computational power. Another advantage is that it provides intuition behind such results as the Kalman filter.
Discussion
The idea behind RLS filters is to minimize a cost function  by appropriately selecting the filter coefficients , updating the filter as new data arrives. The error signal
by appropriately selecting the filter coefficients , updating the filter as new data arrives. The error signal  and desired signal are defined in the negative feedback diagram below:
and desired signal are defined in the negative feedback diagram below:
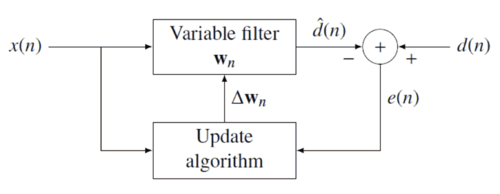
The error implicitly depends on the filter coefficients through the estimate  :
:

The weighted least squares error function —the cost function we desire to minimize—being a function of e(n) is therefore also dependent on the filter coefficients:

where  is the "forgetting factor" which gives exponentially less weight to older error samples.
is the "forgetting factor" which gives exponentially less weight to older error samples.
The cost function is minimized by taking the partial derivatives for all entries  of the coefficient vector and setting the results to zero
of the coefficient vector and setting the results to zero

Next, replace with the definition of the error signal
![{\displaystyle \sum _{i=0}^{n}\lambda ^{n-i}\left[d(i)-\sum _{l=0}^{p}w_{n}(l)x(i-l)\right]x(i-k)=0\qquad k=0,1,\cdots ,p}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f227f57b5708e2279ff63386d33c501f76f500b7)
Rearranging the equation yields
![{\displaystyle \sum _{l=0}^{p}w_{n}(l)\left[\sum _{i=0}^{n}\lambda ^{n-i}\,x(i-l)x(i-k)\right]=\sum _{i=0}^{n}\lambda ^{n-i}d(i)x(i-k)\qquad k=0,1,\cdots ,p}](https://wikimedia.org/api/rest_v1/media/math/render/svg/43bb38e8f5f1fa0bb012d33ae44308679a9707c2)
This form can be expressed in terms of matrices

where  is the weighted sample correlation matrix for , and
is the weighted sample correlation matrix for , and  is the equivalent estimate for the cross-correlation between and . Based on this expression we find the coefficients which minimize the cost function as
is the equivalent estimate for the cross-correlation between and . Based on this expression we find the coefficients which minimize the cost function as

This is the main result of the discussion.
The smaller  is, the smaller contribution of previous samples. This makes the filter more sensitive to recent samples, which means more fluctuations in the filter co-efficients. The
is, the smaller contribution of previous samples. This makes the filter more sensitive to recent samples, which means more fluctuations in the filter co-efficients. The  case is referred to as the growing window RLS algorithm. In practice, is usually chosen between 0.98 and 1.[1]
case is referred to as the growing window RLS algorithm. In practice, is usually chosen between 0.98 and 1.[1]
Recursive algorithm
The discussion resulted in a single equation to determine a coefficient vector which minimizes the cost function. In this section we want to derive a recursive solution of the form

where  is a correction factor at time
is a correction factor at time  . We start the derivation of the recursive algorithm by expressing the cross correlation in terms of
. We start the derivation of the recursive algorithm by expressing the cross correlation in terms of 
where  is the
is the  dimensional data vector
dimensional data vector
![{\displaystyle \mathbf {x} (i)=[x(i),x(i-1),\dots ,x(i-p)]^{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dab2ea44a54d82de74ac9f6d26e3f5f6c2a44d8a)
Similarly we express in terms of  by
by
In order to generate the coefficient vector we are interested in the inverse of the deterministic autocorrelation matrix. For that task the Woodbury matrix identity comes in handy. With
The Woodbury matrix identity follows
To come in line with the standard literature, we define
where the gain vector  is
is
Before we move on, it is necessary to bring  into another form
into another form
Subtracting the second term on the left side yields
With the recursive definition of  the desired form follows
the desired form follows

Now we are ready to complete the recursion. As discussed
The second step follows from the recursive definition of . Next we incorporate the recursive definition of together with the alternate form of and get
With  we arrive at the update equation
we arrive at the update equation
where  is the a priori error. Compare this with the a posteriori error; the error calculated after the filter is updated:
is the a priori error. Compare this with the a posteriori error; the error calculated after the filter is updated:

That means we found the correction factor

This intuitively satisfying result indicates that the correction factor is directly proportional to both the error and the gain vector, which controls how much sensitivity is desired, through the weighting factor, .
RLS algorithm summary
The RLS algorithm for a p-th order RLS filter can be summarized as
| Parameters: |
 filter order filter order
|
|
 forgetting factor forgetting factor
|
|
 value to initialize value to initialize 
|
| Initialization: |
 , ,
|
|
 , ,
|
|
 where where  is the identity matrix of rank is the identity matrix of rank
|
| Computation: |
For 
|
|
![{\mathbf {x}}(n)=\left[{\begin{matrix}x(n)\\x(n-1)\\\vdots \\x(n-p)\end{matrix}}\right]](https://wikimedia.org/api/rest_v1/media/math/render/svg/d85a8706d78172d40a299b2bb60ae26b22a21f6c)
|
|

|
|

|
|

|
|
 . .
|
Note that the recursion for  follows an Algebraic Riccati equation and thus draws parallels to the Kalman filter.[2]
follows an Algebraic Riccati equation and thus draws parallels to the Kalman filter.[2]
Lattice recursive least squares filter (LRLS)
The Lattice Recursive Least Squares adaptive filter is related to the standard RLS except that it requires fewer arithmetic operations (order N). It offers additional advantages over conventional LMS algorithms such as faster convergence rates, modular structure, and insensitivity to variations in eigenvalue spread of the input correlation matrix. The LRLS algorithm described is based on a posteriori errors and includes the normalized form. The derivation is similar to the standard RLS algorithm and is based on the definition of  . In the forward prediction case, we have
. In the forward prediction case, we have  with the input signal
with the input signal  as the most up to date sample. The backward prediction case is
as the most up to date sample. The backward prediction case is  , where i is the index of the sample in the past we want to predict, and the input signal
, where i is the index of the sample in the past we want to predict, and the input signal  is the most recent sample.[3]
is the most recent sample.[3]
Parameter Summary
 is the forward reflection coefficient
is the forward reflection coefficient
 is the backward reflection coefficient
is the backward reflection coefficient
 represents the instantaneous a posteriori forward prediction error
represents the instantaneous a posteriori forward prediction error
 represents the instantaneous a posteriori backward prediction error
represents the instantaneous a posteriori backward prediction error
 is the minimum least-squares backward prediction error
is the minimum least-squares backward prediction error
 is the minimum least-squares forward prediction error
is the minimum least-squares forward prediction error
 is a conversion factor between a priori and a posteriori errors
is a conversion factor between a priori and a posteriori errors
 are the feedforward multiplier coefficients.
are the feedforward multiplier coefficients.
 is a small positive constant that can be 0.01
is a small positive constant that can be 0.01
LRLS Algorithm Summary
The algorithm for a LRLS filter can be summarized as
| Initialization:
|
|
For i = 0,1,...,N
|
|
Template:Pad (if x(k) = 0 for k < 0) (if x(k) = 0 for k < 0)
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:Pad
|
|
End
|
| Computation:
|
|
For k ≥ 0
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:PadFor i = 0,1,...,N
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:PadFeedforward Filtering
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:PadEnd
|
|
End
|
|
|
Normalized lattice recursive least squares filter (NLRLS)
The normalized form of the LRLS has fewer recursions and variables. It can be calculated by applying a normalization to the internal variables of the algorithm which will keep their magnitude bounded by one. This is generally not used in real-time applications because of the number of division and square-root operations which comes with a high computational load.
NLRLS algorithm summary
The algorithm for a NLRLS filter can be summarized as
| Initialization:
|
|
For i = 0,1,...,N
|
|
Template:Pad (if x(k) = d(k) = 0 for k < 0) (if x(k) = d(k) = 0 for k < 0)
|
|
Template:Pad
|
|
Template:Pad
|
|
End
|
|
Template:Pad
|
| Computation:
|
|
For k ≥ 0
|
|
Template:Pad (Input signal energy) (Input signal energy)
|
|
Template:Pad (Reference signal energy) (Reference signal energy)
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:PadFor i = 0,1,...,N
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:Pad
|
|
Template:PadFeedforward Filter
|
|
Template:Pad
|
|
Template:Pad![{\overline {e}}(k,i+1)={\frac {1}{{\sqrt {(1-{\overline {e}}_{b}^{2}(k,i))(1-{\overline {\delta }}_{D}^{2}(k,i))}}}}[{\overline {e}}(k,i)-{\overline {\delta }}_{D}(k,i){\overline {e}}_{b}(k,i)]](https://wikimedia.org/api/rest_v1/media/math/render/svg/580293031a5a01b0b256042558d14b8ae206561d)
|
|
Template:PadEnd
|
|
End
|
|
|
See also
References
- 20 year-old Real Estate Agent Rusty from Saint-Paul, has hobbies and interests which includes monopoly, property developers in singapore and poker. Will soon undertake a contiki trip that may include going to the Lower Valley of the Omo.
My blog: http://www.primaboinca.com/view_profile.php?userid=5889534
- Simon Haykin, Adaptive Filter Theory, Prentice Hall, 2002, ISBN 0-13-048434-2
- M.H.A Davis, R.B. Vinter, Stochastic Modelling and Control, Springer, 1985, ISBN 0-412-16200-8
- Weifeng Liu, Jose Principe and Simon Haykin, Kernel Adaptive Filtering: A Comprehensive Introduction, John Wiley, 2010, ISBN 0-470-44753-2
- R.L.Plackett,Some Theorems in Least Squares,Biometrika,1950,37,149-157,ISSN 00063444
- C.F.Gauss,Theoria combinationis observationum erroribus minimis obnoxiae,1821, Werke, 4. Gottinge
Notes
43 year old Petroleum Engineer Harry from Deep River, usually spends time with hobbies and interests like renting movies, property developers in singapore new condominium and vehicle racing. Constantly enjoys going to destinations like Camino Real de Tierra Adentro.
- ↑ Emannual C. Ifeacor, Barrie W. Jervis. Digital signal processing: a practical approach, second edition. Indianapolis: Pearson Education Limited, 2002, p. 718
- ↑ Welch, Greg and Bishop, Gary "An Introduction to the Kalman Filter", Department of Computer Science, University of North Carolina at Chapel Hill, September 17, 1997, accessed July 19, 2011.
- ↑ Albu, Kadlec, Softley, Matousek, Hermanek, Coleman, Fagan "Implementation of (Normalised) RLS Lattice on Virtex", Digital Signal Processing, 2001, accessed December 24, 2011.
















![\left[\lambda {\mathbf {R}}_{{x}}(n-1)+{\mathbf {x}}(n){\mathbf {x}}^{{T}}(n)\right]^{{-1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f12c798517a6c530e616e5915429e3e16370785e)











![=\lambda ^{{-1}}\left[{\mathbf {P}}(n-1)-{\mathbf {g}}(n){\mathbf {x}}^{{T}}(n){\mathbf {P}}(n-1)\right]{\mathbf {x}}(n)](https://wikimedia.org/api/rest_v1/media/math/render/svg/3baaff4ae27f9cfc51e54ada85a9de0999978262)


![=\lambda \left[\lambda ^{{-1}}{\mathbf {P}}(n-1)-{\mathbf {g}}(n){\mathbf {x}}^{{T}}(n)\lambda ^{{-1}}{\mathbf {P}}(n-1)\right]{\mathbf {r}}_{{dx}}(n-1)+d(n){\mathbf {g}}(n)](https://wikimedia.org/api/rest_v1/media/math/render/svg/d1dfdfb80807912183bd47c28d76f65ea9d4c553)

![{\displaystyle =\mathbf {P} (n-1)\mathbf {r} _{dx}(n-1)+\mathbf {g} (n)\left[d(n)-\mathbf {x} ^{T}(n)\mathbf {P} (n-1)\mathbf {r} _{dx}(n-1)\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9800c914543c33d7b8ebd7f295efc9fdc51b57e7)
![={\mathbf {w}}_{{n-1}}+{\mathbf {g}}(n)\left[d(n)-{\mathbf {x}}^{{T}}(n){\mathbf {w}}_{{n-1}}\right]](https://wikimedia.org/api/rest_v1/media/math/render/svg/78ebe76268d69116b2d676aab45f0272977a6df2)
